LLMs as Markov Chain
前言
几个月之前,Andrej Karpathy 发布了一个推特[1],给出了一个看待语言模型(language model,下称LM)行为的新视角:LM可以看作有限状态的马尔可夫链(finite-state Markov Chain)。在最近一段时间和LLM(large language model)的交互过程中,以这个马尔可夫链的视角作为基础,笔者对于LLM的一些行为有了进一步的理解与认知。写这篇文章,一方面是为了分享Karpathy的观点,另一方面则是帮助大家从实践的视角进一步理解/预测语言模型的一些行为。
本文会在第一个部分介绍LM为什么可以被看作是一个Markov chain;之后会从以这个视角进一步展开,聊一聊Markov chain视角下的Prompt Engineer、In-Context Learning以及一些LM展现出来的有趣特性。
Karpathy的观点
为了照顾一些初学者,这个部分会介绍地尽量详细一些,已经了解为什么LM可以被看作是Markov chain的读者可以跳过这个部分。
想要体验最原汁原味的介绍可以移步Karpathy写的colab[2]。
context length与tokenizer
LM从本质上来看,就是接受一堆文字作为输出,然后不断预测下一个文字的模型。为了通俗一些,我们举一个例子,假设我们有一个窗口大小为4的LM,这个LM接受的输入给LM这样一段话“今天天气”,LM就会预测下一个字是“真”,接着我们把“真”放入“今天天气”后面,同时保持窗口大小不变,LM接受到的输入就是“天天气真”,LM就会预测下一个字是“好”,接着把好放在之前的句子后面,以此类推,最后我们就可以得到“今天天气真好。”的输出。
因为LM的输入需要是固定的长度,为了统一,我们就会称这个固定长度为context length。上文的例子中的LM的context length的就是4,这也就意味着这个LM一次性接受4个词的输入,并且预测下一个词是什么。
但是,LM是无法接受文字作为输入的,对于所有的LM来说,都需要tokenizer将文字输入转换成token。以LLaMA的tokenizer为例子,在不考虑bos(begin of sentence,即<s> )和eos(end of sentence,即</s>)符号的情况下,句子”Hello world”会被转换成 \([15043, 3186]\) 的输入,之后这个输入就可以被LM接收,从而预测下一个单词。
下面的code给出了一个具体的示例来方便理解:
>>> tokenizer.encode("Hello world", bos=False, eos=False)
<<< [15043, 3186]
>>> tokenizer.decode([15043, 3186])
<<< 'Hello world'
为了说明简单,我们后文中的token都采用数字来表示,这样我们就可以把LM的输入看作是一个数字序列,而LM的输出则是一个关于全部token的分布。而tokenizer能够处理的字符集的大小,我们称之为vocab_size。
假设token只有0和1两种(vocab_size为2),context_length 为2,\(\rightarrow\) 表示数据流向,LM推理[1, 0]输入的过程可以表示为:
\[[1, 0] \rightarrow LM \rightarrow [P(0) = 40\%, P(1) = 60\%]\]当然这里预测为0和1的概率是随便给的,只是为了方便理解。
vocab_size与context length决定了马尔可夫链的状态空间
考虑一个最最简单的LM,我们称之为baby-GPT,这个LM的context length为3,token只有[0, 1]两种,那么这个LM的全部状态空间就可以表征为 \([0, 1]\) 的3次笛卡尔积, 也就是说这个baby-GPT的状态空间大小为 \({vocab\_size}^{context\_length} = 2^3 = 8\)。 具体来说,所有的状态空间为 \([0, 0, 0]\), \([0, 0, 1]\), \([0, 1, 0]\), \([0, 1, 1]\), \([1, 0, 0]\), \([1, 0, 1]\), \([1, 1, 0]\), \([1, 1, 1]\)。
考虑一个baby-gpt的特定状态,此处我们以 \([0, 0, 1]\) 为例,将这个状态作为baby-gpt的输入, 对应的输出的形式则类似于 \([P(0) = 45\%, P(1) = 55\%]\),代表下一个token是0或者1的概率。 将这个过程对应到马尔可夫链的角度,我们可以认为 \([0, 0, 1]\) 状态可以转移到 \([0, 1, 0]\) 和 \([0, 1, 1]\) 两个后继状态,转移概率分别为 \(45\%\) 和 \(55\%\) 。
下图给出了baby-GPT在初始状态下的每个状态和对应的转移概率。

从Markov Chain视角看训练
假设开始训练这个baby-GPT,需要训练的数据序列为”111101111011110”,则baby-GPT实际的训练数据则为:
训练数据 01: \([1, 1, 1] \rightarrow 1\)
训练数据 02: \([1, 1, 1] \rightarrow 0\)
训练数据 03: \([1, 1, 0] \rightarrow 1\)
训练数据 04: \([1, 0, 1] \rightarrow 1\)
训练数据 05: \([0, 1, 1] \rightarrow 1\)
训练数据 06: \([1, 1, 1] \rightarrow 1\)
训练数据 07: \([1, 1, 1] \rightarrow 0\)
训练数据 08: \([1, 1, 0] \rightarrow 1\)
训练数据 09: \([1, 0, 1] \rightarrow 1\)
训练数据 10: \([0, 1, 1] \rightarrow 1\)
训练数据 11: \([1, 1, 1] \rightarrow 1\)
训练数据 12: \([1, 1, 1] \rightarrow 0\)
在正常训练了模型之后,我们可以得到一个训练好的baby-GPT的权重,此时baby-GPT的状态转移概率相对初始版本已经发生了变化,如下图所示:

从上图不难看出,相比初始状态,训练后的baby-GPT在 \([0, 0, 1]\) 状态下更容易生成转移到 \([0, 1, 1]\) (概率从 \(55\%\) 提升到 \(78\%\) )。实际上整个baby-GPT相比初始状态,更容易预测下一个token是1,这也符合训练数据特点:1的数量远远大于0。
到这里,基本上大家可以理解为什么LM本质上是一个Markov chain了,也能根据上面提供的例子理解数据是如何影响这个Markov chain的了。
LM as Markov chain的一些性质
本章节讨论LM作为Markov chain会有哪些有趣的性质,以及这些性质对LM的训练和使用有什么启发。
声明:这些性质未必是LLM作为Markov chain一定存在的性质,更多是我个人的看法和符合直觉的思想实验,欢迎提出不一样的看法。
性质与启发
- 第一个性质肯定是稀疏性,这个也很直觉,虽然Markov chain的状态非常多,但是大部分状态之间几乎没有转移概率,因此这个Markov chain是非常稀疏的。
这个性质对LM的训练的启发在于:如果想要让LM在特定场景能够输出一些不常用的字,比如“你”字后面跟个“铋”字,单纯更多地使用“你铋”的话应该是治标不治本的,因为模型是根据context进行转移的,而“你”字只是最后一个token,以“你”字结尾的状态数过于巨大,并不是简单通过加几个训练样本就能解决的。 - 第二个性质在于状态数的指数爆炸性,随着LM的vocab_size和context_length增大,Markov Chain中的状态数是几乎以指数倍增长的,在原始训练数据分布不变的情况下,模型建模的难度是减少的。但如果想要更好的效果,模型需要投喂的数据量可能也需要进行某种(感觉是指数的?)形式的scale。至少从直觉上来说,应该存在某种数据规模和context_length之间的scaling law。除此之外,状态的指数爆炸性也在某种程度上能解释为什么LLM会存在涌现能力,很可能状态数达到了某种足够多的状态之后,完成某个任务的知识的建模起来更加容易了。
- 第三个性质是Markov chain中同构现象普遍存在。这个同构现象是将Markov chain看作一个图,而这个大图中的部分子图是同构的。比如考虑一个同时具有英文和中文能力的LM,“I want to go home”和“我想回家”在tokenizer看来是完全没有任何关系的两句话(因为tokenizer encode出来的结果完全不一样),但是我们如果站在Markov chain的视角去看这两句话在图里面的结构,很可能是非常相似的。不同语言的相似语义保证了这种同构现象的存在。
这个性质对于LM训练的启发在于:如果想要提升LM在某种语言(比如中文)的效果,单纯堆中文语料甚至不一定比中英混合语料更有效。解决A空间中的问题或许可以采用解决空间B中的问题 + 映射回A空间的方式。
展开看LM的特性
首先想聊的是模型的能力(ability)。
在最早看到CoT(Chain of Thought)相关的paper[4]以及“Let’s think step by step.”[5]的魔法提示词(Prompt)之后,我一度不是很理解:通过更改Prompt的方式,模型就比原来更有可能产生期望的输出结果,而且很可能模型在训练阶段都没怎么见到过这个Prompt。 这件事放在计算机视觉领域类比一下,就相当于找到了一个新的图像增强策略,这个增强策略在训练阶段没有使用过,但是却能够在所有的模型上有效提升效果。
到这里就会引出一个新的问题:如何界定一个模型有解决某类问题的能力? 从Markov chain的视角来看,问题本身就是这个链上的一个状态集合A(称之为问题状态集,之所以是个集合是因为同一个问题有很多表示形式,在链上的状态数必然不止一个),而我们期望的答案也是这个链上的一个状态集合B(称之为答案状态集)。只要在这个链上从A到B的转移概率不为0,那么我们就可以认为模型是具有解决这个问题的能力的。用公式表达就是:
\[P_{LLM}(B|A) > 0 \Rightarrow {LLM有能力解决问题A}\]所以说,如果模型在某种Prompt的提示下产生了期望的输出,那么我们就能认为模型本身是具有能力的,只不过被Prompt激发了出来。
有趣的是,在计算机视觉领域,据我所知还没有类似Prompt这种可以激发单一模态的视觉模型能力的方法(大部分没有训练过的数据增强策略都对效果有负面影响)。
其实这个视角同样可以套用到人的身上:如果一个人存在解决某个问题的可能性(解决问题的概率大于0),那我们就能认为这个人是有能力解决这个问题的。
其次想要聊的是LM对于拥有更大信息量的数据的偏好性。
这点其实也很好理解,同样长度的数据,如果LM在看过数据之后,对应的Markov chain中的转移概率没有发生太大的变化,那么这个数据训练与否对LM并没有太大的影响,反倒是一些能够改变Markov chain中转移概率的数据起到的作用更大。换句话说,在训练过程中,LM更倾向于受到具有更大信息量的数据的影响,因为这些数据可以帮助Markov chain建立状态之间的链接,修正状态之间的转移概率。
套用到人身上,就是已知的信息看再多遍也很难有明显的提升,提升自己的能力靠的是寻求新的知识与挖掘看待旧知识的新视角。 而模型的预训练就像人类的学习一样,都是在初始链接的基础上,不断更新状态之间的转移概率,建立更强的状态间的连接。
新视角下的Old things
这个部分我们会站在Markov chain的新视角来看待一些“旧事物”。
Prompt Engineering
在Lilian Weng介绍Prompt Enginerring的blog[3]以及Prompting Guide网站中介绍了很多prompt engineering的方法, 有一些方法对新人来说也许有一些反直觉或者tricky,比如把问题中的”Q”换成”Question”、一开始给LM设定一些特定的角色玩cosplay、 给几个实际样例(few-shot),但是考虑到前文所述我们仅仅是要从问题状态A集找到一条到回答状态集B的一条转移路径,这些方法也就不难理解。
以把原始问题中的”Q”换成”Question”这个trick为例,其所表达的就是下面一个朴素的公式:
\[P_{LLM}(Answer|Q \; type \; Prompt) < P_{LLM}(Answer|Question \; type \; Prompt)\]从Markov chain视角来看上面的公式:“question”状态转移到答案状态的概率,要比和“q”状态转移到答案的概率更高。
通过在输入端改变问题,进而改变问题状态集,并且最终提升转移到答案状态集的概率,这是在Markov chain视角下对于Prompt Engineering的新视角。
In-Context Learning
In-Context Learning(下称ICL),简单来说,就是类似下面的一种场景:
评论: 这个电影太烂了。 态度:消极。
评论: 我好喜欢这个电影。 态度:
模型则会根据输入对应产生输出。
评论: 这个电影太烂了。 态度:消极。
评论: 我好喜欢这个电影。 态度:积极。
在华盛顿大学和meta研究ICL为什么能work的paper[6]里(或者参考斯坦福大学的blog[7]), 研究人员探究了一下到底是输入、输出还是输入-输出的匹配更加重要(参考下图)。
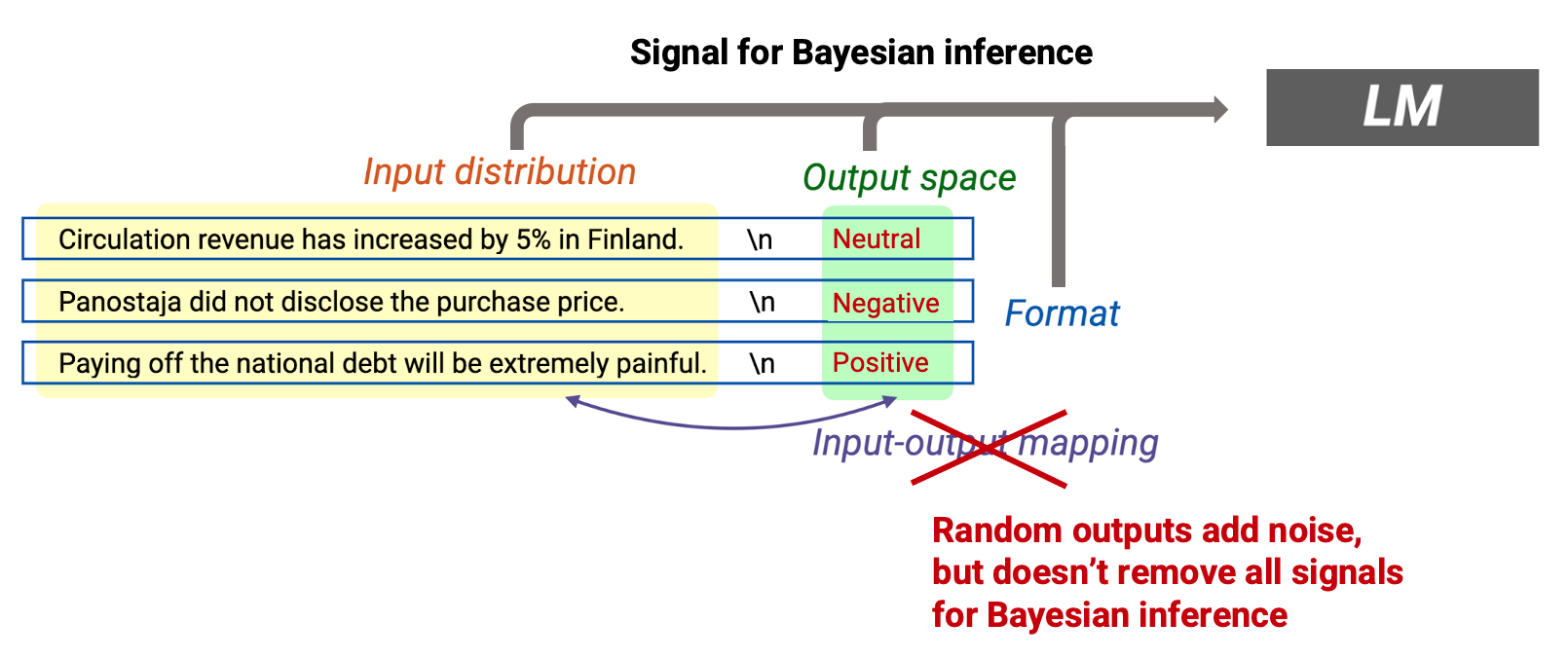
文章给出了一个非常有信息量的实验:输入-输出的匹配并没有想象中那么重要。也就是说,即使将原有标签随机修改,比如上面的示例修改成评论: 这个电影太烂了。 态度:积极。,模型仍然能够产生正确的输出。关键在于保持输入和输出本身的一致性。
结合Markov chain来看待ICL:通过指定问题的输入和输出空间,使得LM在一个固定的子图上游走,使得模型更有可能产生正确的输出。最妙的是,根据实验来看,这个游走过程是不受之前的错误状态引导的。
CoT
“Let’s think step by step.”[5]的魔法Prompt也被称为Zero-shot CoT(Chain of Thought),在使用了这样的prompt之后,模型更容易沿着分解问题的思路解决问题,从而在一些逻辑推理类的任务上产生分步输出,进而获取更接近真实答案的输出。
在Markov Chain中,“Let’s think step by step” 和问题的中间步骤关联,而中间步骤状态相比没有任何输出的状态转移到答案的概率更高。这样来看,想出这个prompt也是很需要insight的。
Random, but not random
这个其实是我观察到的一个很有趣的现象,很多时候LLM是能够理解随机的,但是行为上却绝对做不到最真实的随机。其实从Markov chain的视角来看,这个事情是很容易理解的, 但是可能你去问一些ChatGPT的用户,他们或许也并不能回答这个问题:如果要求ChatGPT完成如下的任务:“从A,B,C,D中随机选择一个”,那么ChatGPT这样的LM能否从做到统计意义上的随机?
答案很显然:肯定不能,而且LM几乎确定不能原生解决这样的问题。要证明这个问题也很简单,以这个“ABCD”的例子 来说明,仅仅考虑当前Markov chain的状态S,考虑后续输出为“A”,“B”,“C”,“D”的四种状态A、B、C、D,要做到统计意义上的随机,Markov chain就一定需要满足下面的公式(不考虑temperature这些因素):
\[P(A|S) = P(B|S) = P(C|S) = P(D|S) = 25\%\]注意公式里面的ABCD只是一个状态的合集,也就是像“A”和“A.“都是A这个集合中的一个元素,所以说LM几乎确定不能解决这个问题。 但是如果引入插件的思想,由LM做控制器来判断需要执行random.choice(["A", "B", "C", "D"])函数,这个问题就非常容易解决了。
Citation
如果觉得有帮助,欢迎引用这篇blog:
@article{wang2023LLM,
title = "LLMs as Markov Chain",
author = "Wang, Feng",
journal = "fatescript.github.io",
year = "2023",
month = "Jun",
url = "https://fatescript.github.io/blog/2023/LLM-markov-chain/"
}
Reference
[1] Karpathy的twiiter
[2] 介绍LLM as Markov Chain的Colab
[3] Lilian Weng介绍Prompt Engineering的blog
[4] Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
[5] Large Language Models are Zero-Shot Reasoners
[6] Rethinking the Role of Demonstrations: What Makes In-Context Learning Work?
[7] How does in-context learning work?